
作者:黄雅馨(广东外语外贸大学 22 法语 MTI)
编辑:陈杲
一、引言
这学期 CAT 课程学习中,字幕翻译部分引起了我比较大的兴趣,与陈老师交流后老师给我推荐了 OpenAI 最近开发的 ASR(自动语音识别)软件 Whisper。在查阅资料后,我发现这一软件的识别效果据说达到了人类水平,且可以识别不同口音,这让我十分好奇,并决定进行测评。作为口译专业的学生,我们平时练习中会接触到大量的视频音频,制作听力文本可以方便我们复习回顾,有时老师也会提供听力文本帮助大家理解,使用 ASR 工具可以让这项工作事半功倍。另外,字幕翻译也是我们学习和工作中可能遇到的翻译类型,在制作视频字幕时,第一步常常要对视频进行语音识别,ASR 工具的使用大有裨益。本文将记录 Whisper 的安装方法(包括 Python、PyTorch、git 和 ffmpeg 的具体安装方式),测评其在特殊口音、背景噪声和技术术语方面法语语音识别效果,并比较 tiny、base 和 medium 三个模型的识别能力,测评部分将使用讯飞的语音识别工具进行对照。
二、Whisper 软件介绍
Whisper 是 OpenAI 在 22 年 9 月开源的一个语音识别系统。Whisper 的一大特点是它使用的超大规模训练集,它使用从网络上收集的 68 万小时(98 种语言)、多任务监督数据进行训练。这导致数据集的内容非常多元化,涵盖了许多不同环境、不同录音设备下、不同语言的音频。具体而言,65%是英语音频和匹配的英语文本,大约 18%是非英语音频和英语文本,而最后 17%则是非英语音频和相应的文本。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。
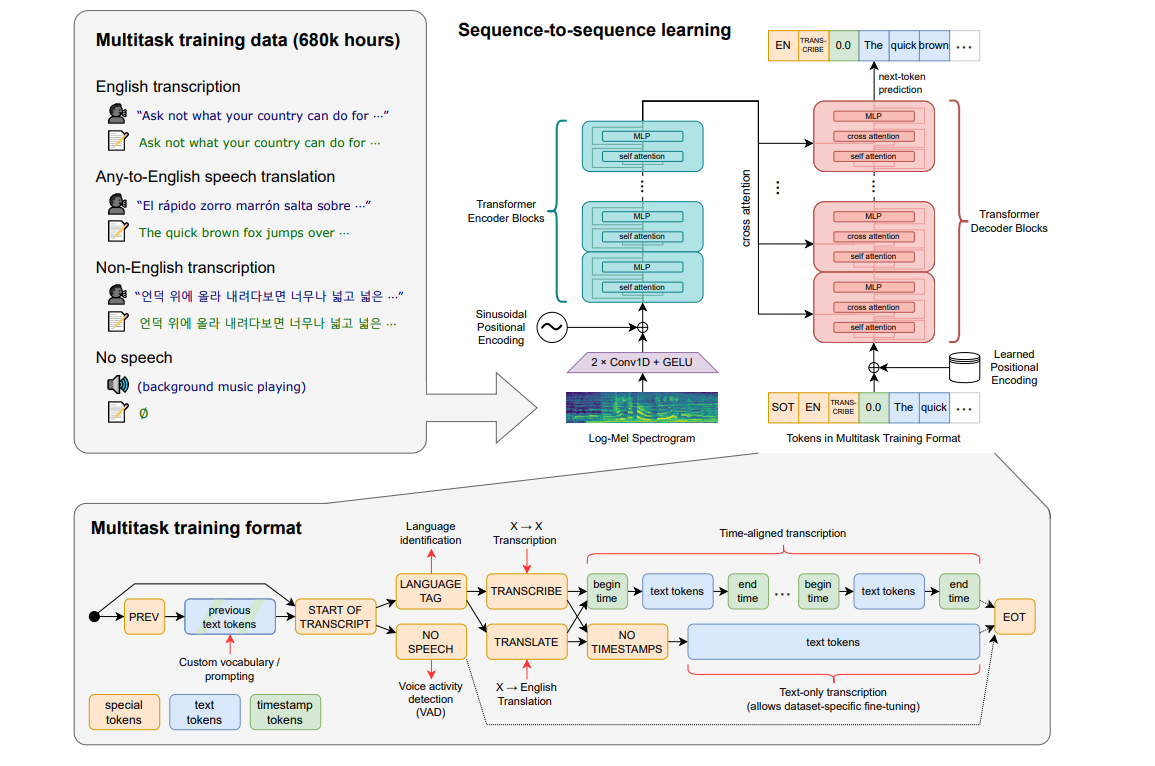
目前 Whisper 有 9 种模型(分为纯英文和多语言),开发者可以根据需求在速度和准确性之间进行权衡,以下是现有模型的大小,及其内存要求和相对速度:
想了解更多信息大家可以访问官方博客https://openai.com/blog/whisper/。
三、Whisper 安装过程
我看到官方给出的安装提示的时候是一头雾水。实际上 Whisper 的安装并不是简单地输入一句命令 pip install whisper 就完事,它使用 Python 编写,用 PyTorch 训练模型,转录部分要利用到 ffmpeg 处理音视频,因此安装请安还需要很多环境准备。考虑到本文的读者应该并非计算机专业,我将较为详细地记录下安装过程,希望能为大家提供参考。
官方使用的是 Python 3.9.9 and PyTorch 1.10.1 来训练和检验的程序,但预计兼容 Python 3.7 以后的版本和 PyTorch 近期更新版本。我在安装 PyTorch 的时候官网显示目前 Windows 版本的 PyTorch 仅支持 Python 3.7-3.9,不支持 Python 2.x 版本。大家在安装时尽量保证 Python 版本与 OpenAI 官方一致或更新版本,或者至少是 3.7 以后版本。本文测试系统为 Windows10 64 位、Python 版本 3.9.9。
PS.安装时请一定保证安装路径中没有中文字符,否则最后运行时会出错。
1. 安装 Python
进入下载页(https://www.python.org/downloads/),点击 Download 按钮,选择电脑系统之后在下拉页面中可以找到之前版本的安装包,根据电脑的配置(32 位或 64 位)选择需要的版本和链接,下载并按照步骤安装即可。
- installer 比较方便,它自带添加到环境变量的功能,但安装的时候需留意勾选 Add Python to PATH,否则要手动配置环境变量。

2. 下载 git 并添加环境变量
在官方网站https://git-scm.com/download/win下载 git 的安装包,安装过程中的选项全都默认,一直点 next 到安装完成。键盘 win+r,调出运行窗口,输入 cmd,回车,打开命令提示符窗口,输入 git,回车,如果命令运行不成功(如下图所示),则需要继续添加环境变量。

添加环境变量的方法如下:
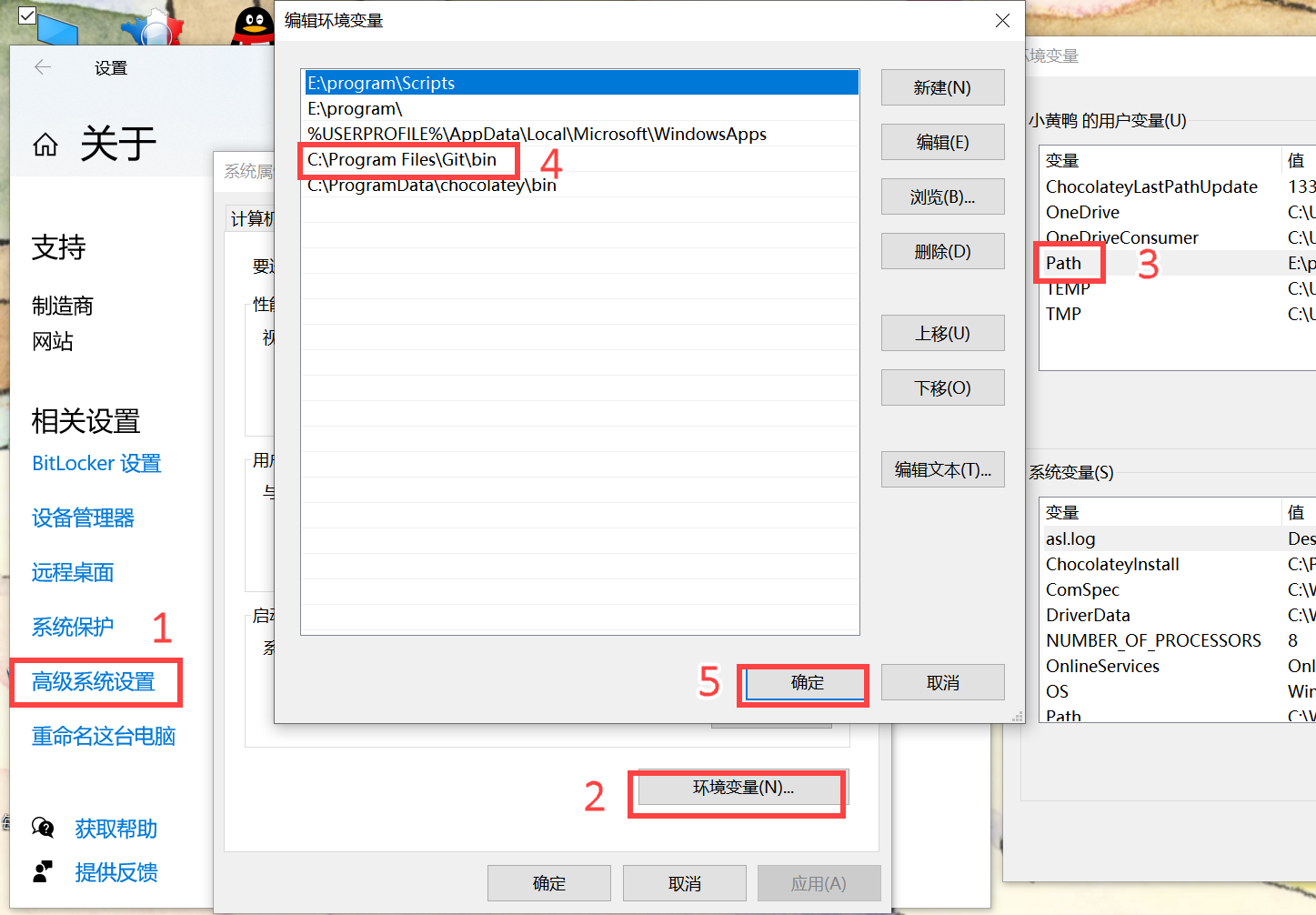
找到 git.exe, 它位于我电脑上的路径是“C:\Program Files\Git\bin”,复制此路径。之后计算机——右键属性——高级系统设置——环境变量——系统变量——选择 PATH——双击在变量值中添加路径。注意每个窗口的确定键都要点击,否则可能添加失败。
3. 下载 ffmpeg 并添加环境变量
可在 https://github.com/BtbN/FFmpeg-Builds/releases 找到“ffmpeg-master-latest-win64-gpl.zip”版本下载,此方法比较方便。
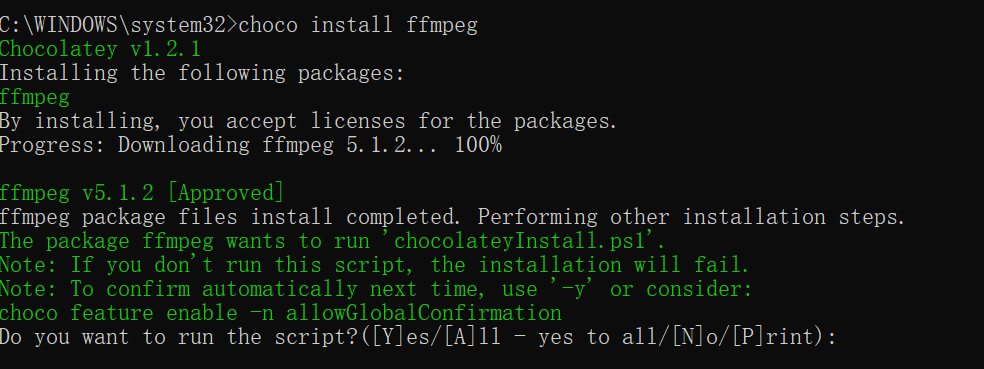
我首先看到了官方提示的下载方法,所以使用了 Chocolatey 进行下载,在此不做详细演示,安装 Chocolatey 之后在 cmd 输入 choco install ffmpeg 运行即可。
PS.安装 Chocolatey 时记得要用管理员身份运行 cmd,用 Chocolatey 安装 ffmpeg 中途会出现 Do you want to run the script? 提示,记得按 Y。
ffmpeg 环境变量的配置方法与 git 基本相同。
4. 下载 PyTorch
打开 https://pytorch.org/,在下拉页面选择了以下版本:稳定版,windows 系统,pip 安装方式,Python 语言、CPU 版本的软件。图中 CUDA 11.6 和 CUDA 11.7 都是 GPU 版本的软件。Whisper 可用 GPU 或 CPU 运行,它对硬件要求比较高,我的笔记本电脑运行中等模型已经非常吃力,如果大家想使用该模型的大型版本,可以在硬件条件允许的情况下使用 GPU(各模型的显存需求如下图)。由于我显卡的显存比较低,可能 base 以上的模型就运行不了,会报显存不足的错误,所以选择了安装 CPU 版本。
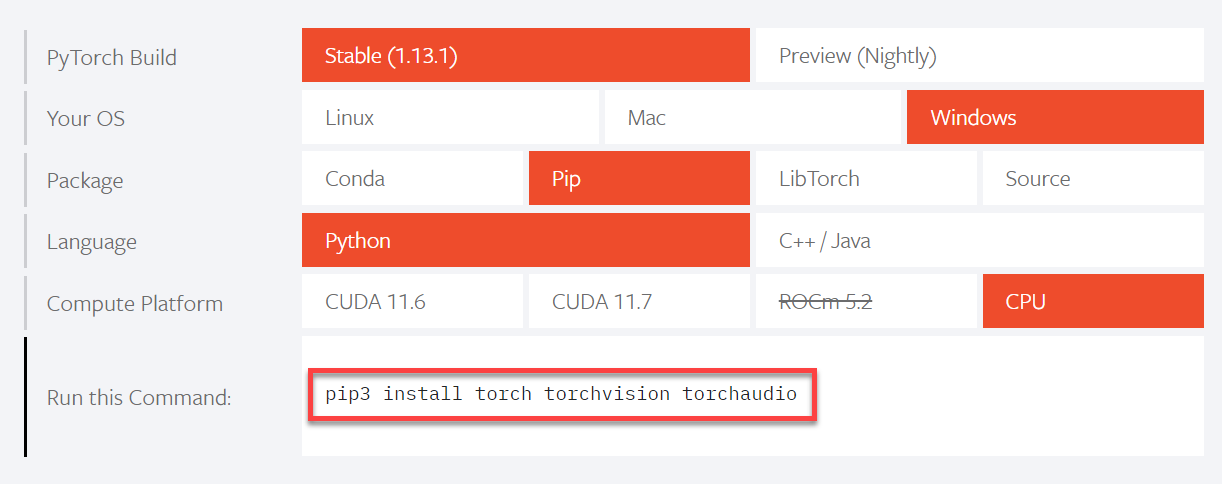

选择好以后最下面一行就是下载此版本的的指令,复制后在 cmd 运行即可。
PS.若出现 ERROR: Exception: Traceback (most recent call last) 报错可能是下载速度太慢导致的,因为原网站是国外网站。我打开 VPN 下载出现了其它类型错误,最后选择了使用国内镜像网站下载,直接在 pip 命令中使用 -i 参数来指定镜像地址,例如:pip3 install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple。
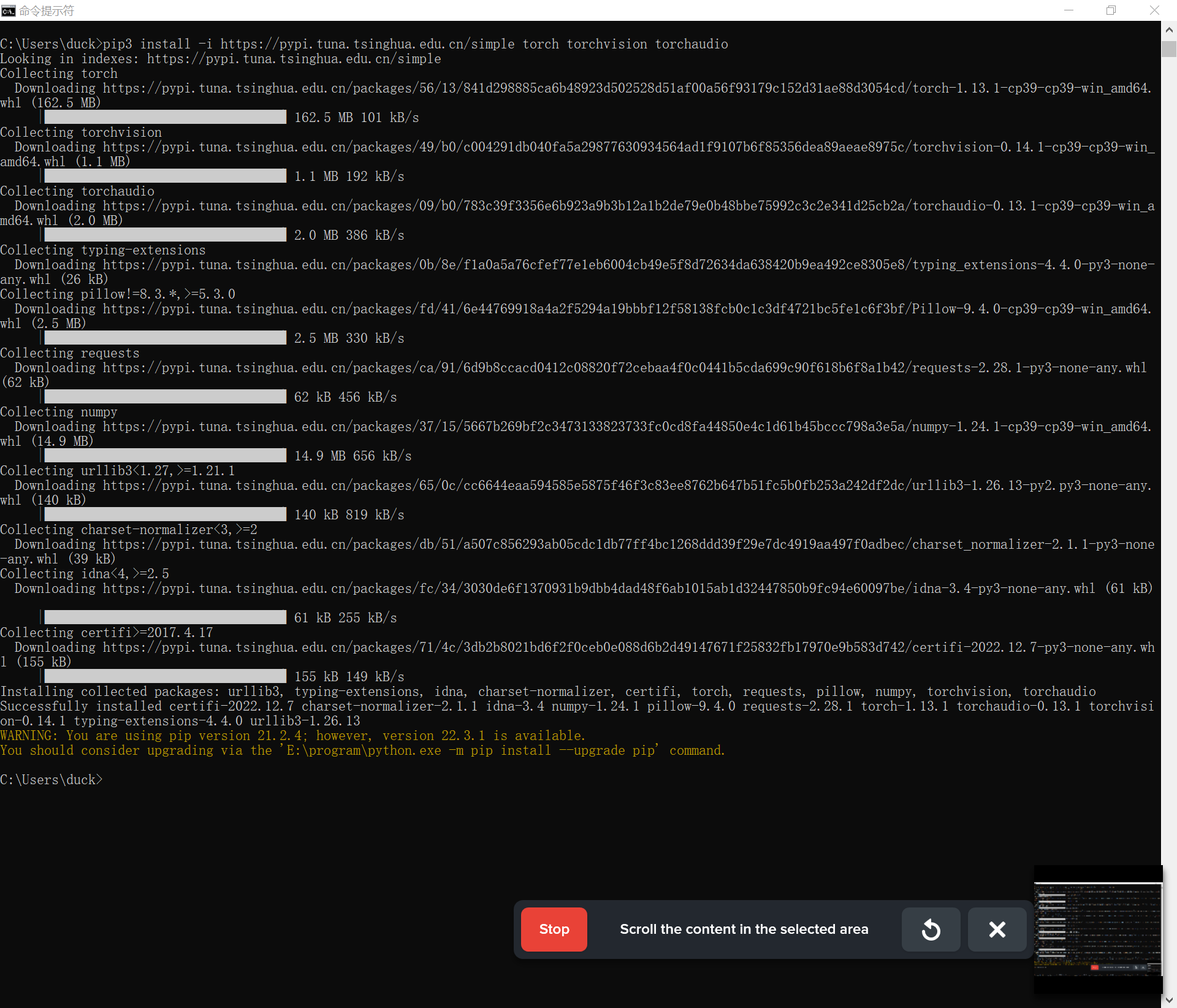
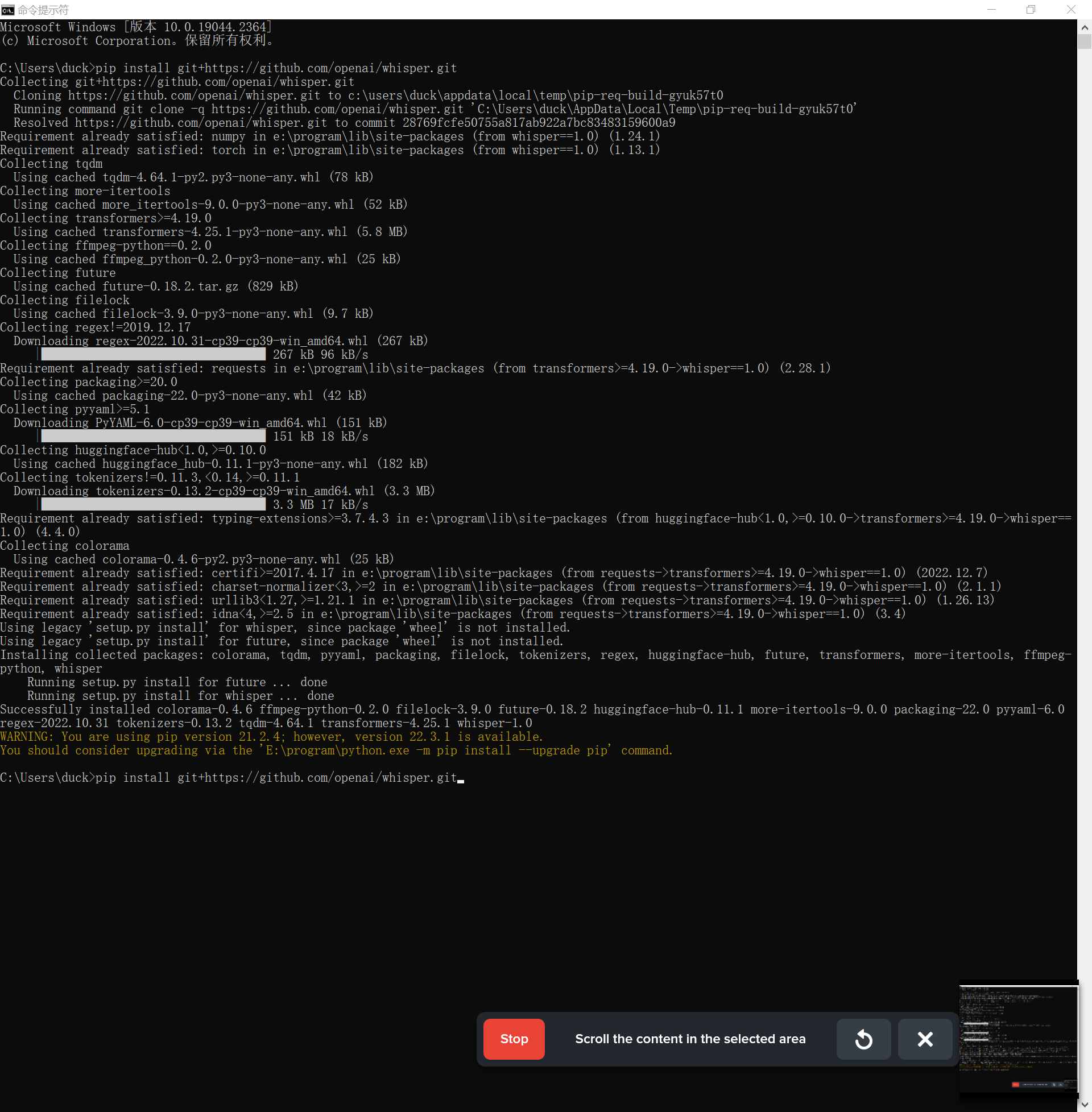
5. 下载 whisper
终于来到了最后一步!按照官方文档指示,先运行 pip install git+://github.com/openai/whisper.git 下载,之后运行 pip install –upgrade –no-deps –force-reinstall git+https://github.com/openai/whisper.git 进行更新,程序就下载好啦!
PS.若出现 ERROR: Command errored out with exit status 128 报错可能是因为开了 VPN 或者网速太慢,可以多试几次或换时间。我晚上下载时一直报错,但第二天上午下载顺利。
6. 使用 Wisper
命令格式举例:
#转录当前文件下名为 audio.mp3 的音频 所有参数设置为默认
whisper audio.mp3
#转录 C 盘目录下名为 audio.mp4 的视频 语言为法语 开启翻译为英文功能 使用 base 模型
whisper C:\audio.mp4 –language French –task translate –model base
有以下模型可选择:
[–model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large}]
选取一段视频(或音频),打开在视频所在文件夹,选中地址栏,输入 cmd 后回车,即可打开此路径的 cmd 窗口。
我选了一段名为 accent 的视频,输入指令 whisper accent.mp4 –language French –model base 后结果如下:
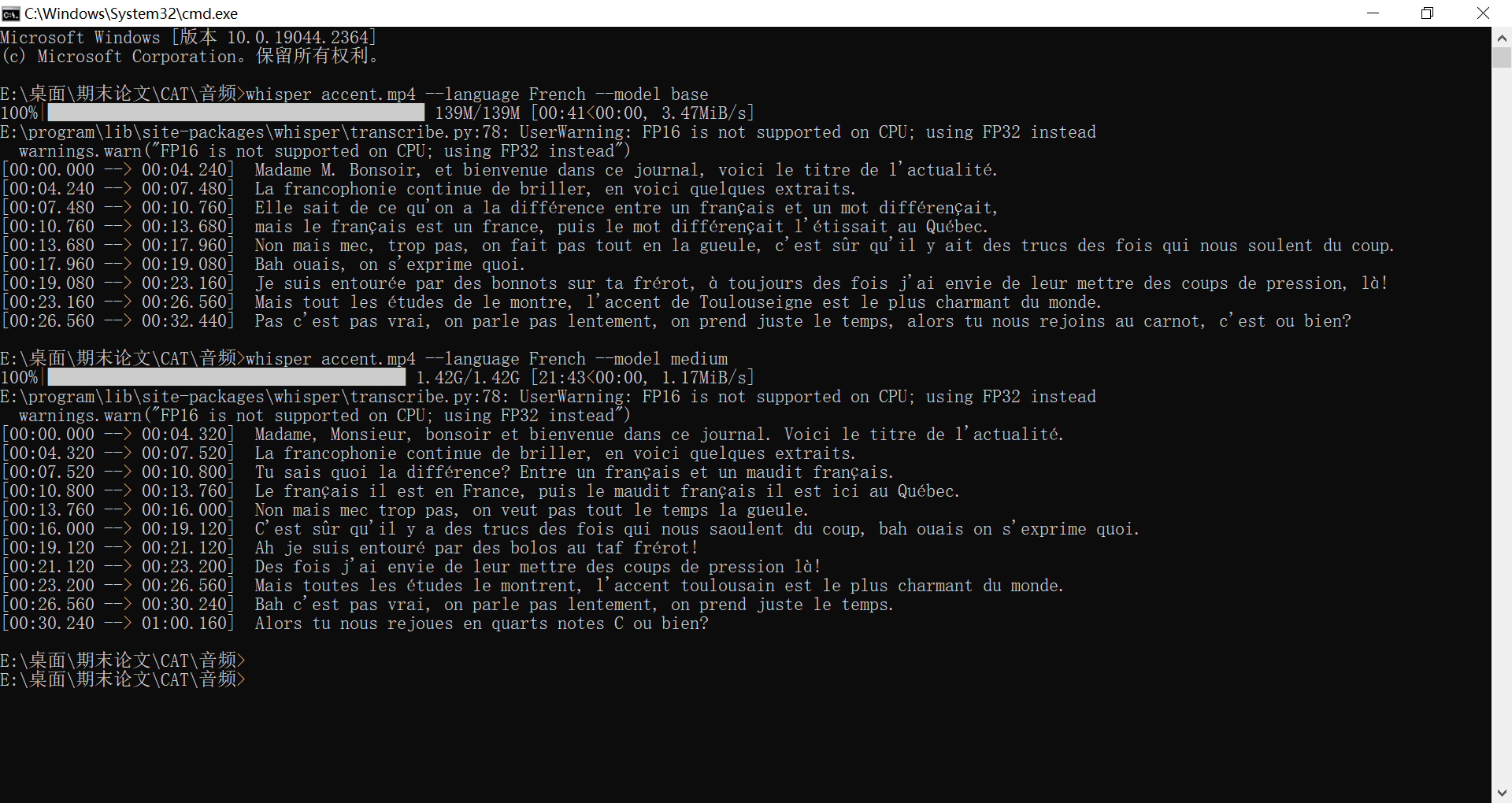
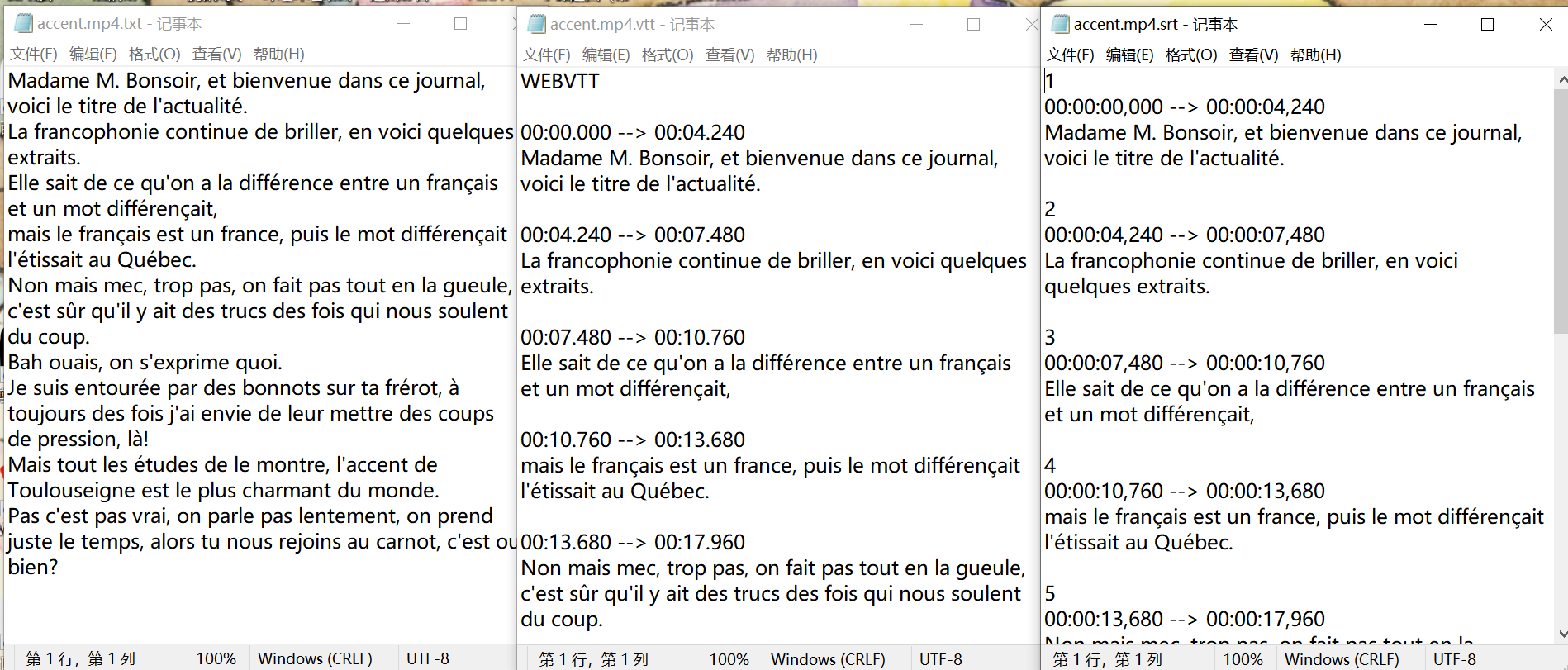
同时,当前文件夹下生成了三种格式的字幕文件:
四、Whisper 和讯飞听见的法语语音识别效果测评
1.对不同类型法语音频的识别效果测评
OpenAl 表示,Whisper 的不同之处就在于它接受了从网络收集的 68 万小时的多语言和多任务训练数据,从而提升了该方案对“独特口音、背景噪声和技术术语的识别能力。”我们就来验证一下它在这几个方面的识别能力是否真的名不虚传。因为我笔记本电脑硬件原因,使用 Whisper 的 medium 模型进行测试,再大一些的模型效果一定更好,但可惜我的电脑无法运行。为了客观地进行评价,我还使用了讯飞听见作为参照。
(1)特殊口音
首先测评两款软件对法语口音的识别能力。用于测试的材料是一段 YouTube 视频,这个博主(big bon)模仿了各地的法国口音,截取的三十秒中包含了标准法语、魁北克法语、巴黎口音、粗俗的法语(racaille)、图卢兹口音和瑞士法语。视频中博主模仿的比较夸张,有些部分语速极快,魁北克法语、巴黎口音和粗俗的法语我基本上只能听懂零星的几个词组。
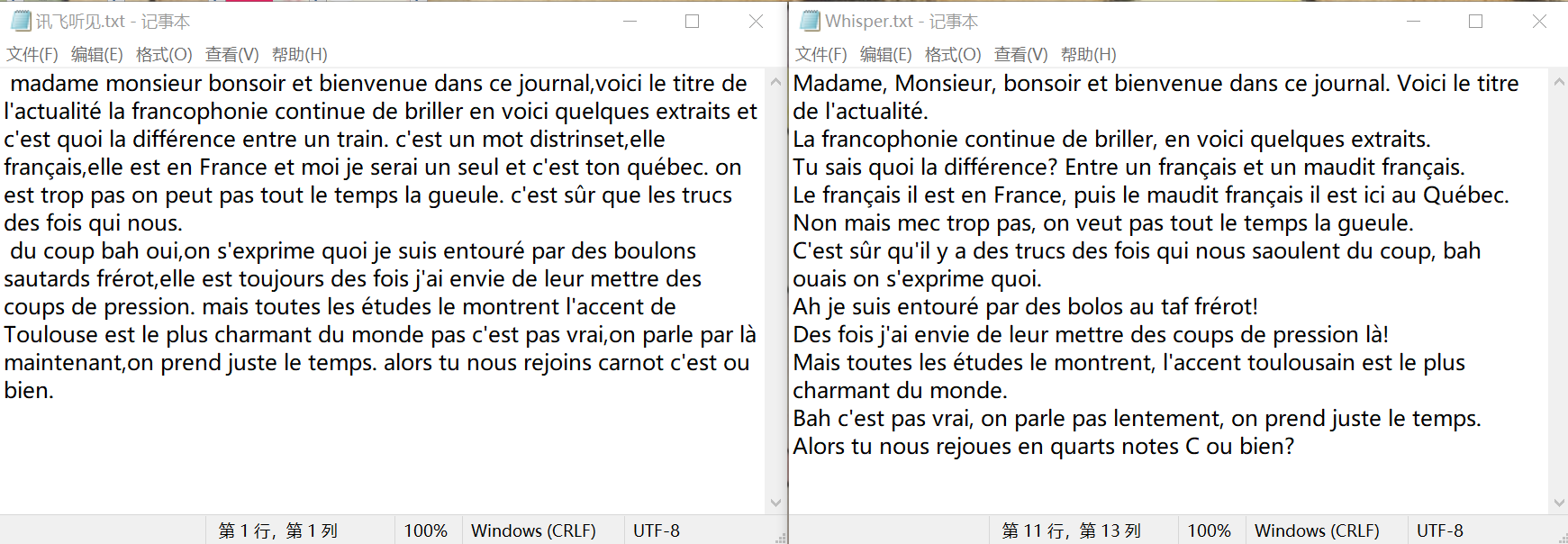
讯飞听见和 Whisper 识别第一句标准法语都完全没有问题。对于后续的 5 种口音,讯飞识别效果比较一般,在魁北克法语、巴黎口音和粗俗的法语部分,讯飞每句可以识别正确几个单词和词组,识别正确的部分基本也是我可以听懂的部分,图卢兹口音和瑞士口音我基本可以听懂,但讯飞识别起来仍然比较困难。
Whisper 对口音的识别效果非常惊艳,medium 模型已经基本可以识别正确以上所有口音。整段总共只有四五个单词出现了错误,而且这些地方博主的语速非常快,吞音严重,我对照字幕也有些听不出来。
(2)背景噪音
测试素材由我自行录制,我用电脑播放了一段餐厅中噪音的音频,同时读了一段介绍七国集团的法语文本,并用手机录音。为了增加识别难度,在录制时噪音的音量被我开得很大,噪音音量应该是大于我朗读的音量的,我即使读过原文本,想要听清录音内容也有一定困难。
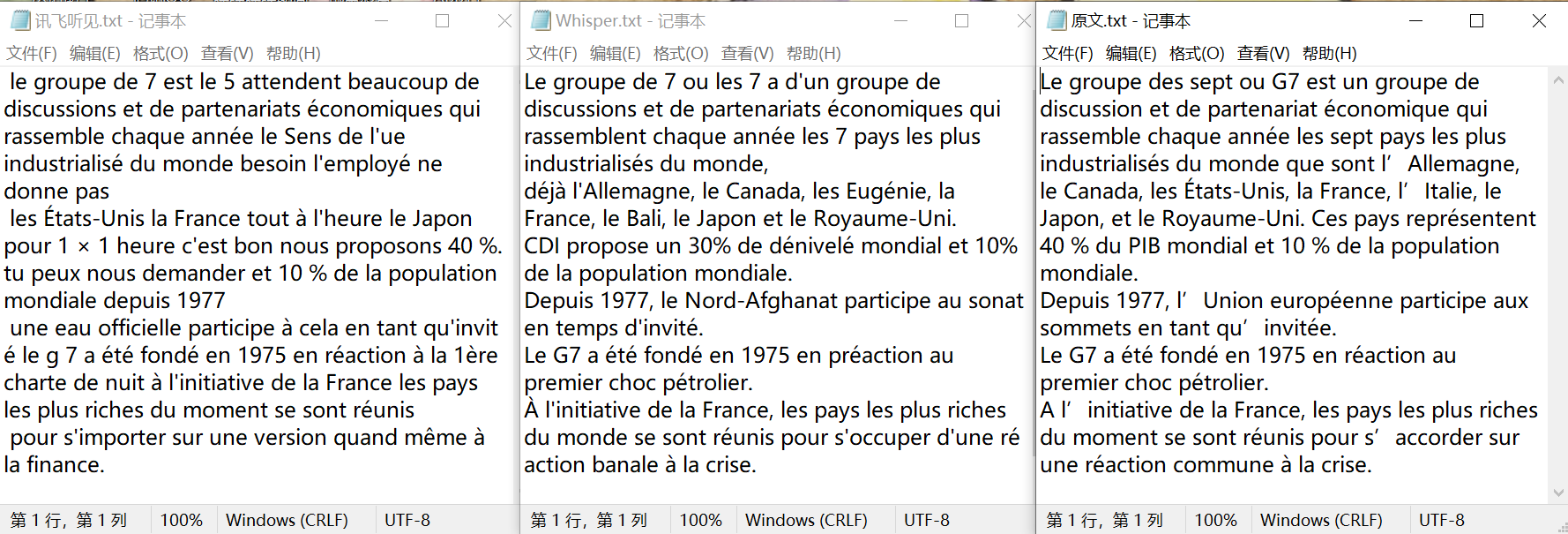
从转写结果来看我的这段录音确实给两款软件造成了一些困难。讯飞听见在转写时每句都有不少漏掉的地方,可能是和噪音混淆了,错误也比较多,大意没能转写出来。Whisper 的识别效果整体不错,漏掉的词只有三四个,错误也少于讯飞,每句大概有两三个单词有误,读起来比较通顺,大意是正确的。
(3)技术术语
专业术语方面我选择了一段介绍氢能的种类和生产方式的视频,涉及到一些化学知识,包含了类似 hydrocarbure(碳氢化合物)、ammoniaque(氨水)、électrolyse(电解作用)、dihydrogène(二氢)等的术语。
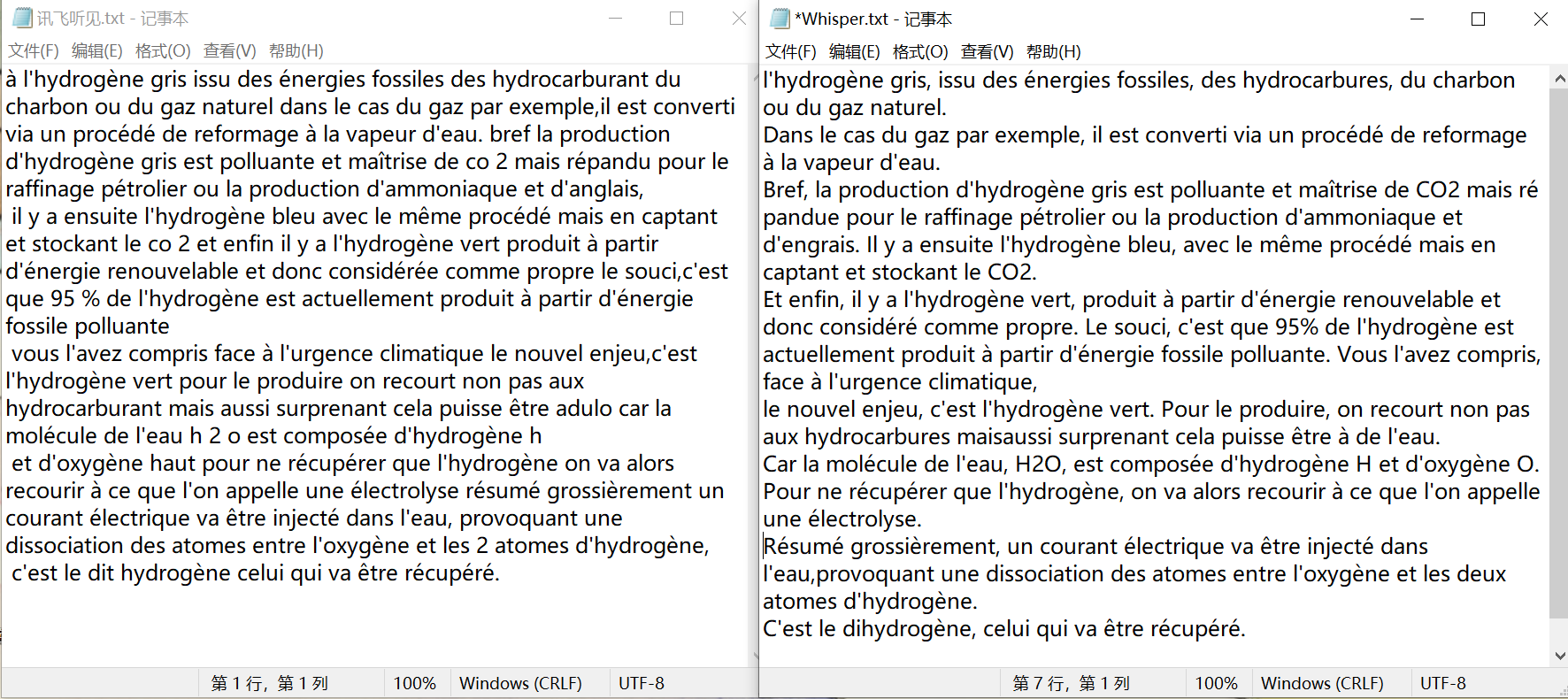
这段音频由于没有其他因素干扰,两款软件识别效果都还不错。讯飞听见在四五个地方有误,engrais(肥料)、dihydrogène(二氢)没有识别出来。讯飞没有进行断句,所以如果要做转写文本还要进行不少工作,包括断句、加标点和改大小写。Whisper 的识别完全准确,没有任何错误,而且标点和大小写也基本没有要更改的地方,CO2 之类的词也自动大写了,已经是一个比较完整的转写文本。此外,视频中有一句“H2O 由氢 H 和氧 O 组成”,“氧 O”的地方讯飞转写的是“oxygène haut”(类似于“氧哦”),Whisper 仍然转写正确,确实比较智能。
2.Whisper 的 tiny、base、medium 模型和讯飞听见的识别效果对比
除仅支持英文的模型外,Whisper 有 5 种模型:tiny、base、small、medium 和 large。我的电脑运行 medium 已经非常缓慢,一分钟的音频可能要翻译半小时,所以模型对比我只好放弃 large 模型,在此就选取 tiny、base 和 medium 进行对比。实际上在硬件达标的情况下,Whisper 的转写速度是很快的,例如 Tesla T4 以上可以在 6 秒左右用 large 模型转录 30 秒的音频。
接下来我用 Whisper 不同模型和讯飞听见转写口音测试的音频:
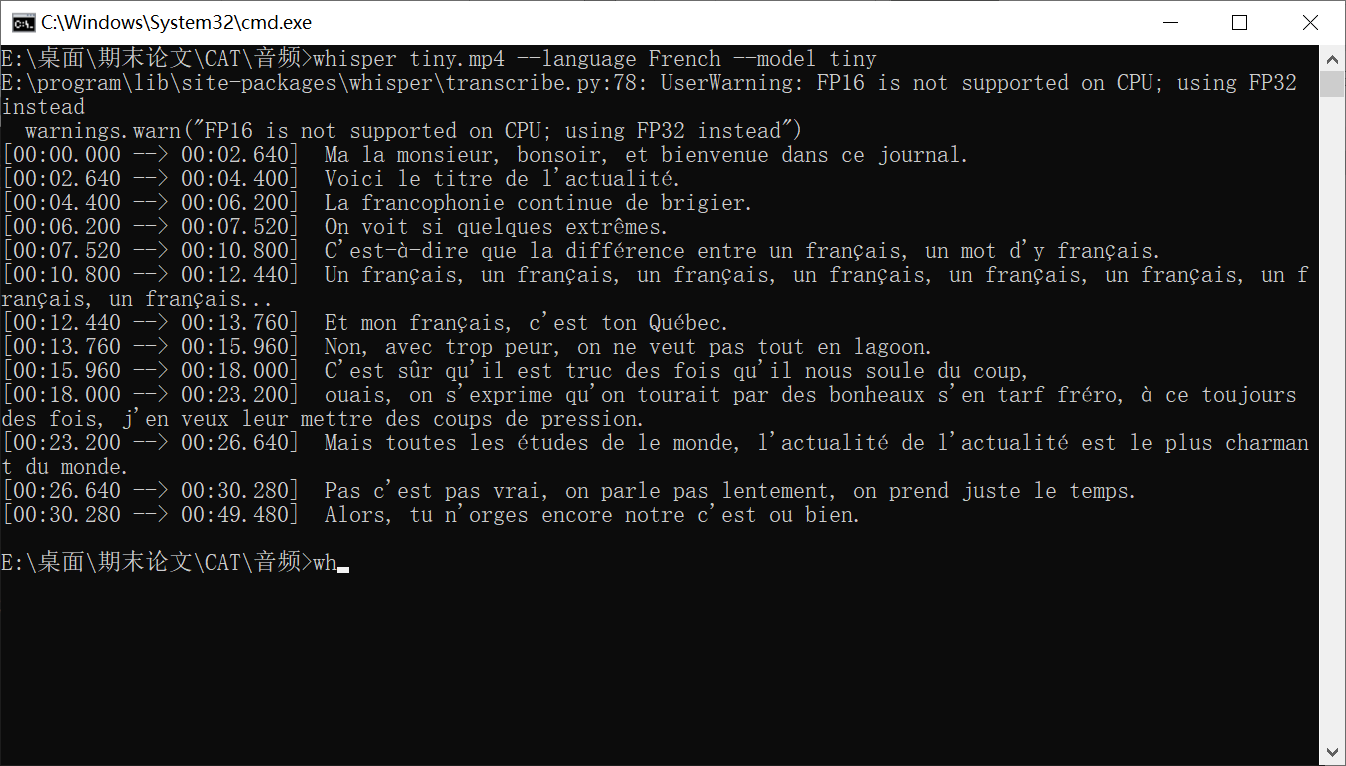
base 和 medium 模型运行结果
从上图可以看出,tiny 模型断句比较粗糙,很多地方是直接根据停顿进行断句的。语音识别不准确,五六个词种就有一个出错,意思很不完整。而 base 模型的识别效果有了很大改进,断句正确,会根据逻辑进行断句,意思比较连贯,对标准法语的识别基本没有问题。除了对魁北克法语识别困难以外,其它部分大意是正确的。最后 medium 模型的识别效果进一步提升,断句准确,意思连贯,语音识别准确高提升,全篇只有三四个地方有误。
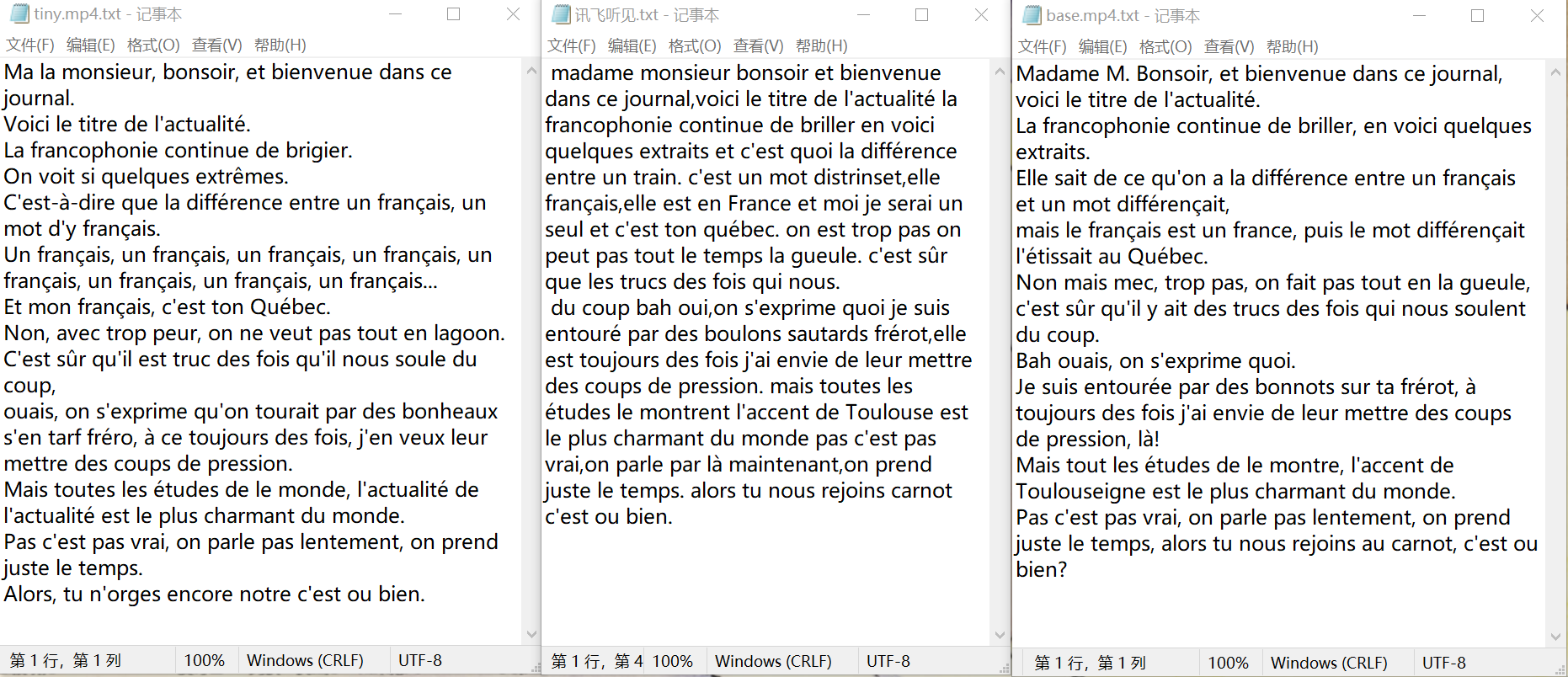
对比发现,讯飞听见的识别能力大概在 Whisper 的 base 模型和 medium 模型之间。虽然讯飞没有进行断句,但它在词汇识别上比 Whisper 的 tiny 模型要准确一些,例如 tiny 模型种,madame 这样比较简单且读音清晰的词汇也会出现识别问题,讯飞听见对这类词汇识别较为准确。讯飞的识别效果与 Whisper 的 base 模型还有一些差距。
五、结论
总之,Whisper 的法语语音识别效果十分惊艳,它在特殊口音、背景噪声和技术术语方面都有出色的转写能力,即使音频转写难度非常高,也能很好地完成工作。而且我在测试中仅仅使用了 medium 模型,如果使用 large 模型相信效果一定更佳。讯飞听见的识别能力大概在 Whisper 的 base 模型和 medium 模型之间。Whisper 唯二的不便可能就是它对硬件要求比较高,以及安装过程对计算机基础弱的人不是特别友好。
碎碎念
陈老师推荐这个软件的时候我完全没想到它如此复杂,过程中几度怀疑自己是否能进行下去,以及电脑能否撑住,中途桌面不见了一次,第一次运行 medium 模型的时候 CPU 疯狂散热让我很担心(后面就习惯了)。许多错误尝试了很久才找到解决方法,第一次安装时在最后一步运行过程中因为文件路径中有中文而出错,我尝试更改用户文件名,没想到导致了更复杂的一系列错误(在此提醒大家,如果想改用户文件夹名,请谨慎考虑使用注册表界面更改,最好使用管理员账户登录后修改;最初设置电脑用户名的时候最好用英文),但改完仍然无法运行,痛心疾首,但也只能尝试全部删掉重下。虽然现在我的电脑还有一些软件打不开,但能成功运行真的非常开心!测评过程(刁难软件)也非常有意思!程序也强大又实用!感谢陈老师的推荐和帮助,感谢小红鱼泡着温泉还在回答我对 Python 的疑问,感谢我的电脑,你承受了太多。
参考链接
OpenAI 博客 https://openai.com/blog/whisper/
Whisper 论文下载 https://arxiv.org/abs/2212.04356
Whisper 官方文档 https://github.com/openai/whisper/
Python 下载 https://www.python.org/downloads/
git 下载 https://git-scm.com/download/win
ffmpeg 下载 https://github.com/BtbN/FFmpeg-Builds/releases
PyTorch 下载 https://pytorch.org/
讯飞听见 https://www.iflyrec.com/html/addMachineOrder.html
专业术语视频 https://www.youtube.com/watch?v=2N6GwxEDmEQ