
作者:于扬(北京外国语大学 19 级德语口译 MTI)
编辑:陈杲、曾慧玲
一、选题背景
无论作为一名翻译学习者,或是未来即将成为职业翻译的译员来说,无论在笔译课堂上,还是在平常接触到的翻译任务中,都会遇到各种各样的原文本,一部分文本以易于编辑的 Word 格式呈现,这是比较理想的源文本状态,因为译者可以将此类文本拿来直接进行编辑;但是,还有一部分如 .pdf 或 .jpg 等图片形式呈现的文本,拿到这类文本就需要译者首先对其进行文本的预处理,将其转换为可编辑的模式,这对译者来说无疑是增大了译前准备的工作量。当然,在实际的工作过程中,尤其是在专业的翻译公司做译员,可以要求客户或者任务发出者提供可编辑的文本;在对方无法提供或无意提供的情况下,就需要译员自己对原文本进行预处理,自然也会产生额外的费用,由此可得出,作为一名译员,掌握文本预处理的基本方法就显得十分重要,也是为真正进入翻译步骤需要做的必要准备。
在学习本学期《计算机辅助翻译》这门课程之前,笔者在日常学习以及实习过程中就曾遇到过这种情况,拿到了无法直接对其进行编辑的源文本,由于当时缺乏使用计算机翻译辅助工具的意识,以及没有掌握使用工具的丰富经验,而采取过一些极为低效的处理办法,比如较短一些的篇章,甚至采用过自己对照着文本逐字逐词编辑成一份新的 Word 文本的方法,造成了翻译之外巨大的工作量, 更导致作为译员付出整体的时间精力与回报不等值的结果。因此,学习如何高效准确地对源文本进行预处理成为了笔者对本节课程最大的期待。
我们日常接触到的PDF 文本很大一部分是由Word 文本直接输出为PDF 格式, 以免在传输过程中发生文本格式的变动,使用 Acrobat Reader 软件就已能够实现编辑功能;或者使用 WPS 便能够将整个 PDF 文本转换成可编辑的 Word 格式, 虽然目前非 WPS 会员或非稻壳会员只能免费转第 1 至 5 页,但从内容的完整度和格式的还原度来讲,已非常成熟。因此,该类文本的转换不是笔者亟待解决的问题重点。
还有一类 PDF 文本,是实体纸质文本扫描或是拍照过后而形成的,因此上述的两个软件有些不太适用,对比如今市面上常见的几款扫描件或照片文档的编辑软件,如“扫描全能王”,市场反应还原度、准确度较高,但是目前遗憾的是国内只有手机版在通行,还没有在 PC 端可供使用的软件版本。鉴于此,在本课程授课教师陈杲老师的推荐下,笔者自本学期以来主要使用 PC 版“捷速 OCR 文字识别软件”对上述此类文本进行预处理,其中收获了一些经验,同时发现了一些有待提升的方面,现与大家做一下分享。
二、软件简介
笔者目前使用的是 PC 版“捷速 OCR 文字识别软件”V7.5.8.3 版本。

以下为笔者在其官网上找到的关于该软件功能特点的官方描述:

以下为软件 PC 版的开始界面,主要有:
- 极速识别
- OCR 文字识别
- 票证识别
- 语音文字互转
- 文档翻译
共 5 大功能,本文主要对前两个功能“极速识别”与“OCR 文字识别”中部分功能进行测评。
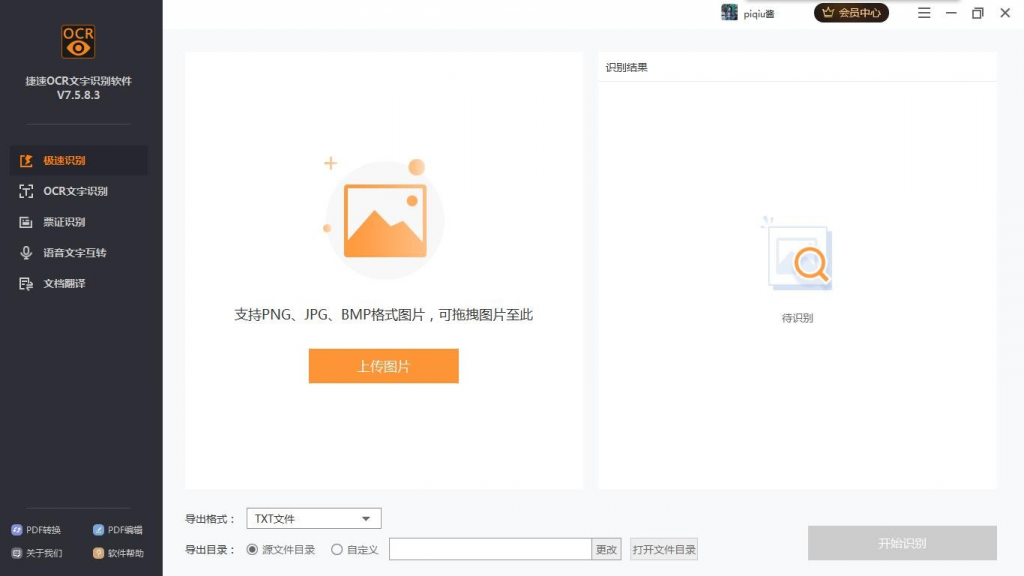
其中“极速识别”功能下支持上传图片文件或可以选择直接拖拽。识别后的文本导出格式为 TXT。
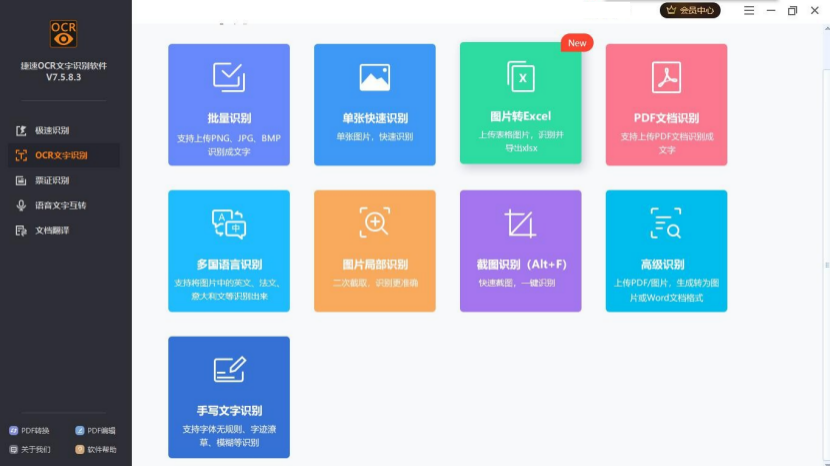
而“OCR 文字识别”功能下分别有:
- 批量识别
- 单张快速识别
- 图片转 Excel
- PDF 文档识别
- 多国语言识别
- 图片局部识别
- 截图识别
- 高级识别
- 手写文字识别
总计 9 大功能,这里识别后的文本导出格式可有 DOC、DOCX 以及 TXT 三种格式。
三、流程演示
鉴于笔者所攻读的专业为德语口译专业,平时主要接触的两种源语为中文和德文的文本,目前已有许多用户做过中文文本,以及使用较为广泛的英文文本识别测评,因此笔者这篇文章将聚焦德文作为源语的文本,简而言之,我们将探究利用这款软件是否能够准确完整的识别出德文,以供翻译时进行文本编辑。下面以笔者处理过的一篇德语篇章为例做演示:

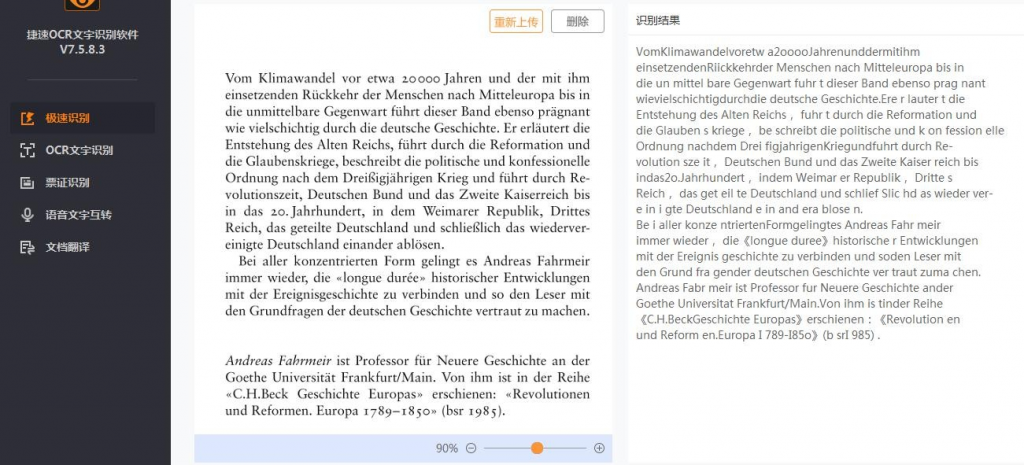
以上是笔者兼职时收到的一项试译任务,但当时对方能够提供的仅为这张图片,是一本德国历史书的一页扫描图,文本内容主要是这本书的前言。接下来将会分别尝试用该软件的不同功能选项进行文字识别提取,并进行成果对比。
- 识别尝试 1:极速识别
首先拖拽图片或点击“添加文件”,点击“开始识别”,识别结果会在几秒之内呈现在右侧,可选择直接复制粘贴到空白文本或导出为 TXT 格式。
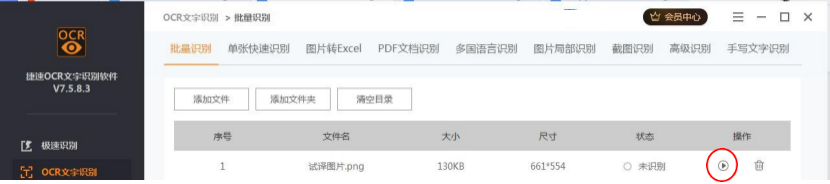
- 识别尝试 2:OCR 文字识别-批量识别
首先点击“批量识别”,拖拽图片或添加文件,点击下方灰色三角或点击“开始识别”,识别成功后,呈现绿色提示,识别结果以与源文件同名并根据选择自动生成 DOC、DOCX 或 TXT 三种格式的文档,点击途中“文件夹”图案,即可打开文档。

- 识别尝试 3:OCR 文字识别-多国语言识别
首先点击“多国语言识别”,选择相应的语种“德语”,拖拽图片或添加文件,点击“开始识别”,识别时间较前两种较长一些,识别结束后。识别结果呈现在右侧,可选择直接复制粘贴到新建空白文档或点击“导出识别结果”,最终导出为同名的 DOC、DOCX 或 TXT 三种格式的文档。
四、使用体验反馈与思考
(一)对比反馈:
- 用时效果对比:“尝试 3”用时较前两者稍长一些,但从效果来看,该软件中选择不同识别方式,三者的结果并不存在明显差别。
- 完整度:鉴于笔者选用的测试图片中文本的字体为一般的印刷体,排除了因为字体复杂而导致难以识别的情况,因此完整度整体很高。
- 准确度:除了文本的完整度,能否准确识别出德文中的特殊字母也是笔者的一大衡量标准,德文与英文字母存在一定的区别,德语字母中有 ä、ü、ö、Ä、Ö、Ü、ß 几个特殊字母,而且德文的双引号特殊,为下引+上引,即 „“,显然在这方面的准确度有待提高。
例如,三个识别结果都将“Rückkehr”一词中的“ü”的错误地识别为了“ii”。
- 整词识别:德语当中有许多复合词,因此导致了许多长单词的产生,而这些长的复合词应连在一起,中间没有空格,笔者发现测试中遇到长单词,识别结果会在词中出现空格,将整个词语断开,或是在许多短词连续出现时,词语词之间缺少应有的空格。
例如,第一句开头“Vom Klimawandel vor etwa…”四个词中间应由 3 个空格隔开, 但识别结果为“VomKlimawandelvoretw a…”,而且由于空格出现错误,将最后一个单词拆成了“etw”和“a”。
(二)思考:
笔者曾多次利用该软件测试识别中文与英文图片文本,效果要相对好于德语文本,特别是准确度更高。面对本次测评中呈现的三个识别结果,都需要笔者利用一些时间,对生成的 Word 文本再进行人工处理,个别字母错误尚可批量替换处理,但是空格问题较为突出,且根据德语构词的特殊性需要逐个人工修改,工程较大,因此若需要大批量识别德文图片或德文扫描文本,笔者目前不太建议使用该软件,期待今后该软件的研发者能够改进优化德语等小语种的识别精准度, 进一步提升用户体验。
本文为作者 CAT 课程期末论文,未经作者允许,不得转载。